Production Grade Code in the Cloud Era
A guide outlining the best practices for running production-grade code in the cloud.
Read on Medium (opens in a new tab)
I have always thought that writing code is more than merely writing a set of instructions for a computer to follow. Programming can be graceful, meaningful, and quite beautiful in the hands of a proper programmer. However, becoming a skilled programmer takes experience and many lessons learned over the years (so don’t be too hard on yourself).
Kubernetes, Docker and cloud technologies in general have changed the expectations of applications running in production. As developers, we would not have full access to applications in production environments due to various SRE and security reasons. With all these considerations, writing better code is more important than ever.
In this article, I thought of sharing my thoughts based on my experience in writing code as well as reviewing code, as a developer as well as a team lead, in the industry working on multiple large-scale cloud-native applications. Moreover, this article includes several well-established practices along with my thoughts on this subject. While I may not go into depth into each area, I hope this will help you get started in thinking like a pro.
Without further ado, let’s get started.
Handling Errors
Expected as well as unexpected errors will occur in software running in production. For example, while you may not encounter errors such as connection failures in development time, these are more common than you think in production. Therefore, handling these in graceful ways is quite important.

While the exact way to handle these will change based on the language and framework you are using, there are a few things to keep in mind when it comes to handling errors in a production environment.
- Either return (or throw based on the language you are using) or log errors properly — never ignore errors. Most frameworks and languages will explicitly specify errors that may occur and it’s important to handle these without simply ignoring them.
- Only return the bare minimum details (never return all the error details or any of the stack trace in exceptions/errors) back to the end users as otherwise, it will expose unnecessary internal information to malicious users. At this point, it is important to log all the information as error logs so that the errors can be debugged if needed.
- It can be quite useful to add a catch-all error handler at the base of the resource/function (in some frameworks you can handle this easily — for example using interceptors for HTTP resources) in your service to handle any unexpected and unknown errors that may occur. It is acceptable to send a generic error such as “Unknown Error” to the user in these scenarios if all the information required for debugging is properly logged.
Graceful Shutdown
In many applications, we use resources (e.g.:- opened files, database connections) which need to be cleaned up or we may have incoming user requests/tasks which need to be completed. In a proper application, we need to handle these gracefully without abruptly stopping them when an application is shutting down.
In Kubernetes especially, restarts of applications can be a common occurrence. Generally, Kubernetes or any management software which looks after your applications will send a SIGTERM OS signal (or SIGKILL when immediate shutdown is required) when it wants to forcefully shut down an application. These can be quite common due to many reasons such as node maintenance tasks in data centers.
As developers, we should handle these shutdown requests gracefully (for example in Java you can use shutdown hooks to handle this) and clean up and complete any currently running tasks so that the users are impacted less in such situations.
Think like a Hacker
Security is an important aspect that cannot be stressed enough in cloud-native applications. While there are many best practices built around security such as the usage of prepared statements in databases, there is still a lot more to improve on security.
While we can spend several articles covering the different ways security can be compromised in an application, there is one important thing when it comes to security.
Think like a Hacker!

As humans, we tend not to see issues in our work. However, training yourself to think of different ways how you as a hacker can exploit your application can help you identify many security holes.
Especially take care and examine the points of interactions that are exposed to the users, as it can impact the result and side effects of your application. For example, the values provided for query parameters in an HTTP service may allow users to get information about other users if a proper authorization logic is not implemented.
Most importantly, think about how you can change the behavior of your application using the inputs provided to your application. When you put on the hat of a hacker for this, stepping outside the box of your use case and changing your goal to break the system, would help you make your applications more and more secure.
Observable Applications

This is where Observability comes into the picture.
For an application to be observable, it should be possible to infer its internal state based on its outputs. There are three main ways to achieve this without compromising the user experience, performance, and security of an application.
Logs
Logs are an important part of any application and you should be careful in selecting a proper logging framework from the start. In general, all important events happening in the application should be logged (selecting the proper log level for your logs to not overwhelm log collection agents is important as well).
- Include information that would help you debug the error — do not assume that you will be able to debug your code in production.
- Use a request/task ID — since many applications need to handle concurrent requests, it can be hard to distinguish logs printed from one request from another without an ID to correlate logs together. A random UUID generated for each of these concurrent requests/tasks would be the solution for this issue.
- Use log levels wisely — it can be quite costly (in terms of money as well as performance) to write logs in production environments. Moreover, properly marking warning and error logs can help SRE to identify issues easily.
- Use debug logs with the information required for debugging — Since it’s general practice to only enable the info log level in production, you can log all the actions in your application as debug logs so that they can be enabled when there is a production issue.
- Do not add Personal Identifiable Information (PII), tokens, or any other sensitive information into logs.
Distributed Tracing
Micro-services had been gaining a lot of traction over the years and even if you are not a fan of them, chances are that, in most cases, you have at least a few separate applications interacting with each other to fulfill an overall goal.
Tracing is an additional layer of observability that is capable of tracking your application across multiple services. Therefore, it would be worthwhile to implement tracing if you are working on a large-scale distributed application.
While I am not planning on explaining distributed tracing in detail in this article, there are a few things to note after you get to know about distributed tracing.
- Add the current trace ID and span ID to the logs so that the trace spans can be correlated with the logs.
- Use samplers — tracing all requests in your application can have a performance impact. Therefore it is important to pick a sensible sampling rate for your application (I would recommend using a rate-limiting sampler that samples a constant number of traces within a unit time period).
- Implement proper propagation of trace context over incoming and outgoing requests for tracing across multiple services.
- Do not trust the trace context that can be passed on by users — a malicious user can sample all requests by sending a tampered trace context into your application.
Metrics
While metrics may not seem important at first glance, they can be quite handy as they will help in implementing an overall dashboard of all applications when dealing with a large-scale deployment.
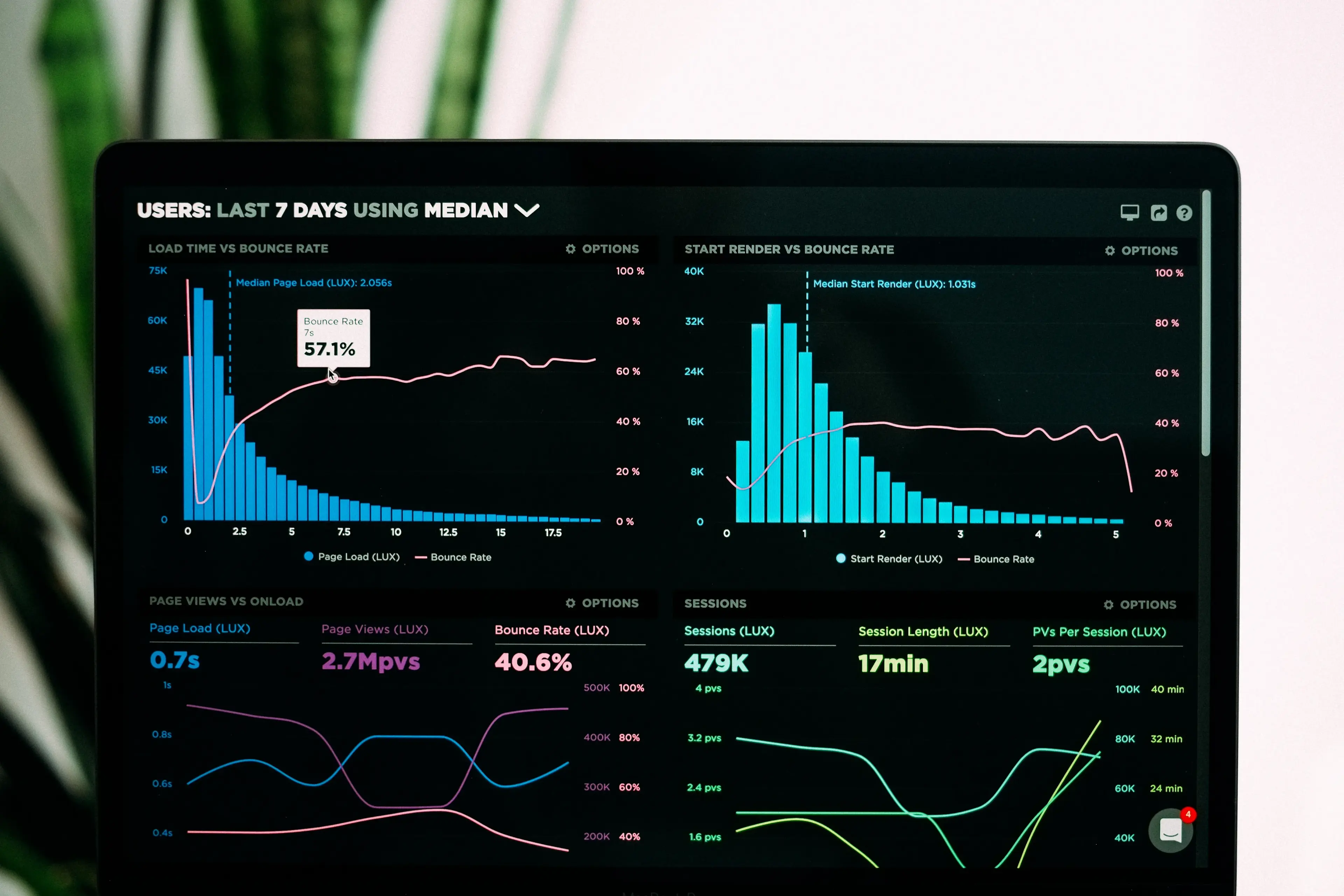
A set of metrics covering things such as the errors that occurred in the application, total traffic, latency in handling requests/tasks (or any other information that is important to you) can help you spot issues in advance.
For all the above (logs, distributed tracing, and metrics), OpenTelemetry has been gaining traction over the last few years, as a widely accepted specification. This was introduced by CNCF and it is being adopted by most of the popular observability tools and platforms such as Jaeger and Prometheus. Therefore, this can be a good starting point if you are not sure where to start at.
Health Probes
In Kubernetes (as well as many other cloud deployment solutions), health probes are an important aspect that should be implemented properly. In many cases, these probes will be used in different ways (e.g.:- for sending alerts for SRE teams, generating availability dashboards for users, automatically restarting services if they are unhealthy, etc.).
Therefore, for your applications to function properly, it is important to implement the health probes properly. While the best practices may vary from one framework/use case to another, the important aspect to remember is to capture properly what constitutes as healthy for your application in the health probe endpoints.
Clean & Readable Code

The importance of clean and readable code had been highlighted by many people over the years. If you have ever had to fix a bug in a code someone wrote many years ago, you would know the importance of this.
There are simple steps that you can take to ensure your code is readable by any poor soul who will need to fix a bug in the future.
- Make your variables as self-explanatory as possible — most compilers & transpilers today optimize and minimize your code. Therefore extra few characters in your variable names would not harm anyone.
- Use nouns for variables and verbs for methods and see how your code itself becomes a story telling how it works.
- Do not misuse comments — your code should be all the explanation it needs. Try to think of exactly what you are doing and make the code meaningful (this will help you reduce the number of bugs in your code as well).
- Use comments only when you write a complex algorithm that can benefit from a brief explanation.
- Set up static code checks and code style checks built into your CI/CD flows from the start — no project is too small not to configure tools as an extra layer of validation.
Most importantly, keep in mind that someone else would need to read your code and understand it somewhere in the future.
Think of the Bigger Picture
Last, but not least, always think about the bigger picture of what you are working on. While some projects can get too complex to know the full breadth of them, it would always help to know as much as possible so that you can write better code catering to different possibilities.
Thinking from different angles and pondering on the what-ifs of your application can give you the extra boost that you need to become a great developer among many good developers.
Finally, while all these are very sensible things to follow, always think and rely on your judgment. Every program you write is unique and there can always be exceptions.
Hope my two cents on writing production-grade code helped you become a better developer. Please feel free to reach out to me if you need any clarifications.